OpenLLM: Operating LLMs in production


Project description

🦾 OpenLLM












An open platform for operating large language models (LLMs) in production.
Fine-tune, serve, deploy, and monitor any LLMs with ease.
📖 Introduction
OpenLLM is an open-source platform designed to facilitate the deployment and operation of large language models (LLMs) in real-world applications. With OpenLLM, you can run inference on any open-source LLM, deploy them on the cloud or on-premises, and build powerful AI applications.
Key features include:
🚂 State-of-the-art LLMs: Integrated support for a wide range of open-source LLMs and model runtimes, including but not limited to Llama 2, StableLM, Falcon, Dolly, Flan-T5, ChatGLM, and StarCoder.
🔥 Flexible APIs: Serve LLMs over a RESTful API or gRPC with a single command. You can interact with the model using a Web UI, CLI, Python/JavaScript clients, or any HTTP client of your choice.
⛓️ Freedom to build: First-class support for LangChain, BentoML, OpenAI endpoints, and Hugging Face, allowing you to easily create your own AI applications by composing LLMs with other models and services.
🎯 Streamline deployment: Automatically generate your LLM server Docker images or deploy as serverless endpoints via ☁️ BentoCloud, which effortlessly manages GPU resources, scales according to traffic, and ensures cost-effectiveness.
🤖️ Bring your own LLM: Fine-tune any LLM to suit your needs. You can load LoRA layers to fine-tune models for higher accuracy and performance for specific tasks. A unified fine-tuning API for models (LLM.tuning()) is coming soon.
⚡ Quantization: Run inference with less computational and memory costs with quantization techniques such as LLM.int8, SpQR (int4), AWQ, GPTQ, and SqueezeLLM.
📡 Streaming: Support token streaming through server-sent events (SSE). You can use the /v1/generate_stream endpoint for streaming responses from LLMs.
🔄 Continuous batching: Support continuous batching via vLLM for increased total throughput.
OpenLLM is designed for AI application developers working to build production-ready applications based on LLMs. It delivers a comprehensive suite of tools and features for fine-tuning, serving, deploying, and monitoring these models, simplifying the end-to-end deployment workflow for LLMs.
💾 TL/DR
For starter, we provide two ways to quickly try out OpenLLM:
Jupyter Notebooks
Try this OpenLLM tutorial in Google Colab: Serving Llama 2 with OpenLLM.
Docker
We provide a docker container that helps you start running OpenLLM:
docker run --rm -it -p 3000:3000 ghcr.io/bentoml/openllm start facebook/opt-1.3b --backend pt
[!NOTE] Given you have access to GPUs and have setup nvidia-docker, you can additionally pass in
--gpusto use GPU for faster inference and optimizationdocker run --rm --gpus all -p 3000:3000 -it ghcr.io/bentoml/openllm start HuggingFaceH4/zephyr-7b-beta --backend vllm
🏃 Get started
The following provides instructions for how to get started with OpenLLM locally.
Prerequisites
You have installed Python 3.8 (or later) and pip. We highly recommend using a Virtual Environment to prevent package conflicts.
Install OpenLLM
Install OpenLLM by using pip as follows:
pip install openllm
To verify the installation, run:
$ openllm -h
Usage: openllm [OPTIONS] COMMAND [ARGS]...
██████╗ ██████╗ ███████╗███╗ ██╗██╗ ██╗ ███╗ ███╗
██╔═══██╗██╔══██╗██╔════╝████╗ ██║██║ ██║ ████╗ ████║
██║ ██║██████╔╝█████╗ ██╔██╗ ██║██║ ██║ ██╔████╔██║
██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║██║ ██║ ██║╚██╔╝██║
╚██████╔╝██║ ███████╗██║ ╚████║███████╗███████╗██║ ╚═╝ ██║
╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝╚══════╝╚══════╝╚═╝ ╚═╝.
An open platform for operating large language models in production.
Fine-tune, serve, deploy, and monitor any LLMs with ease.
Options:
-v, --version Show the version and exit.
-h, --help Show this message and exit.
Commands:
build Package a given models into a BentoLLM.
import Setup LLM interactively.
models List all supported models.
prune Remove all saved models, (and optionally bentos) built with OpenLLM locally.
query Query a LLM interactively, from a terminal.
start Start a LLMServer for any supported LLM.
start-grpc Start a gRPC LLMServer for any supported LLM.
Extensions:
build-base-container Base image builder for BentoLLM.
dive-bentos Dive into a BentoLLM.
get-containerfile Return Containerfile of any given Bento.
get-prompt Get the default prompt used by OpenLLM.
list-bentos List available bentos built by OpenLLM.
list-models This is equivalent to openllm models...
playground OpenLLM Playground.
Start a LLM server
OpenLLM allows you to quickly spin up an LLM server using openllm start. For example, to start a phi-2 server, run the following:
TRUST_REMOTE_CODE=True openllm start microsoft/phi-2
This starts the server at http://0.0.0.0:3000/. OpenLLM downloads the model to the BentoML local Model Store if it has not been registered before. To view your local models, run bentoml models list.
To interact with the server, you can visit the web UI at http://0.0.0.0:3000/ or send a request using curl. You can also use OpenLLM’s built-in Python client to interact with the server:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
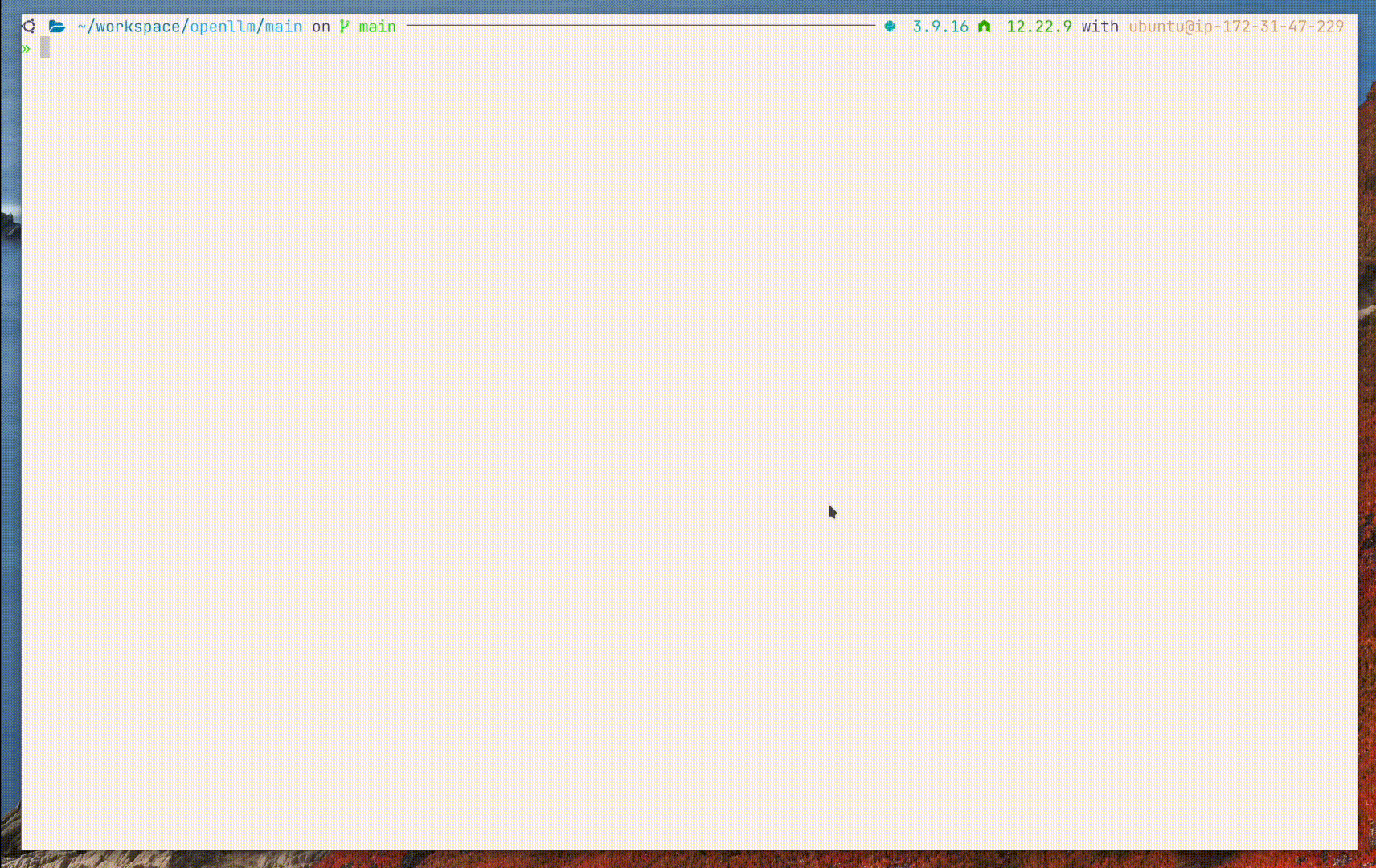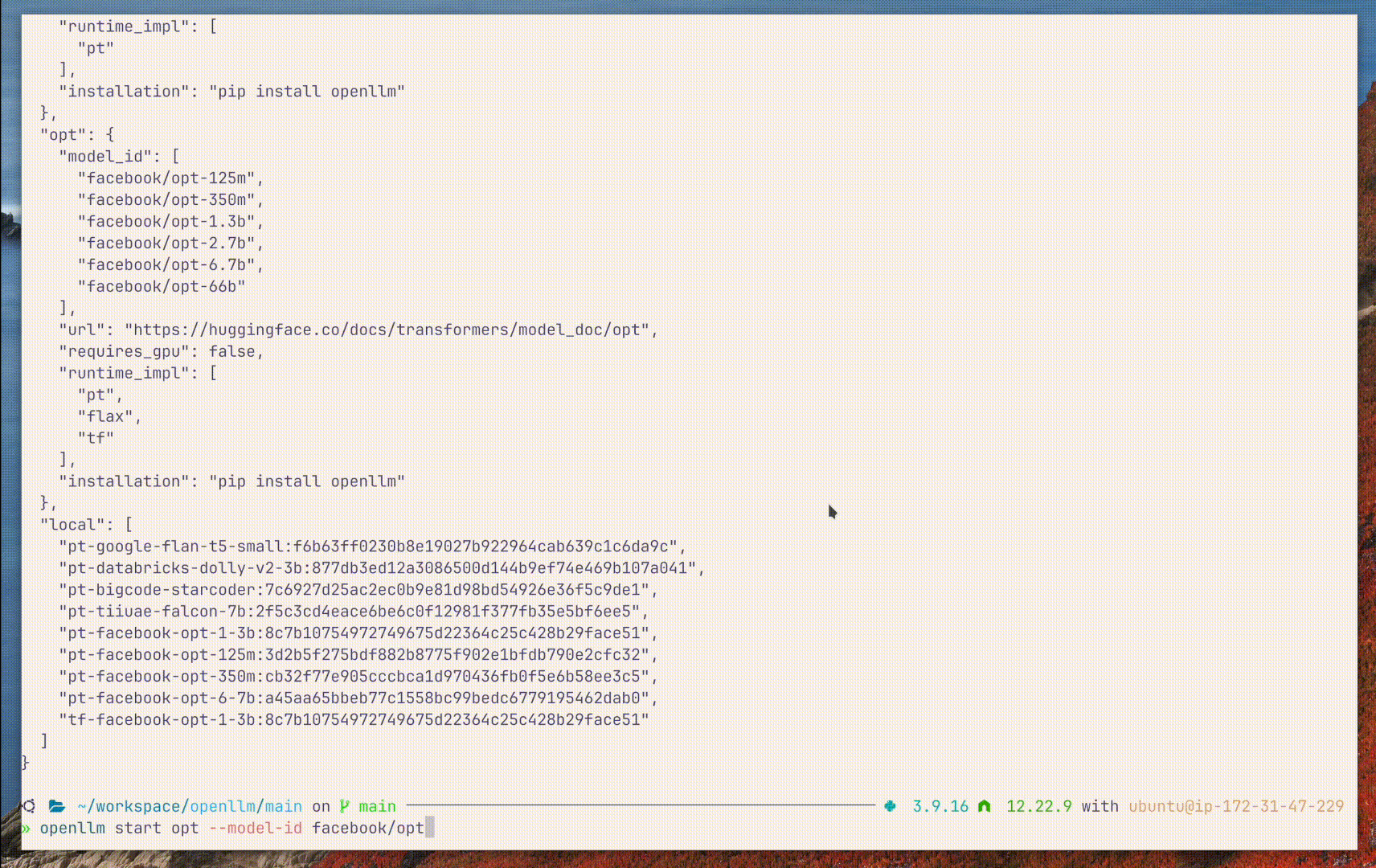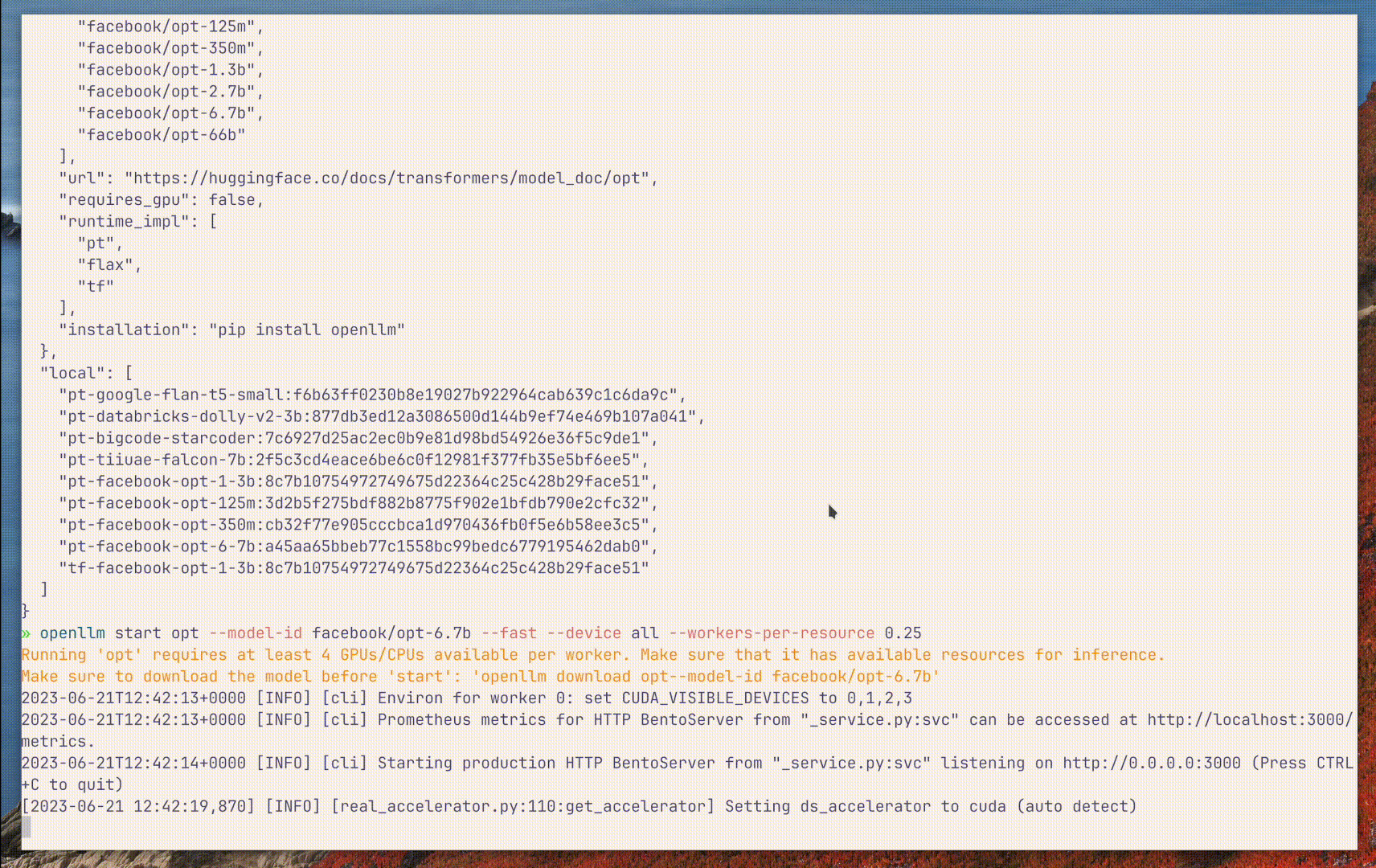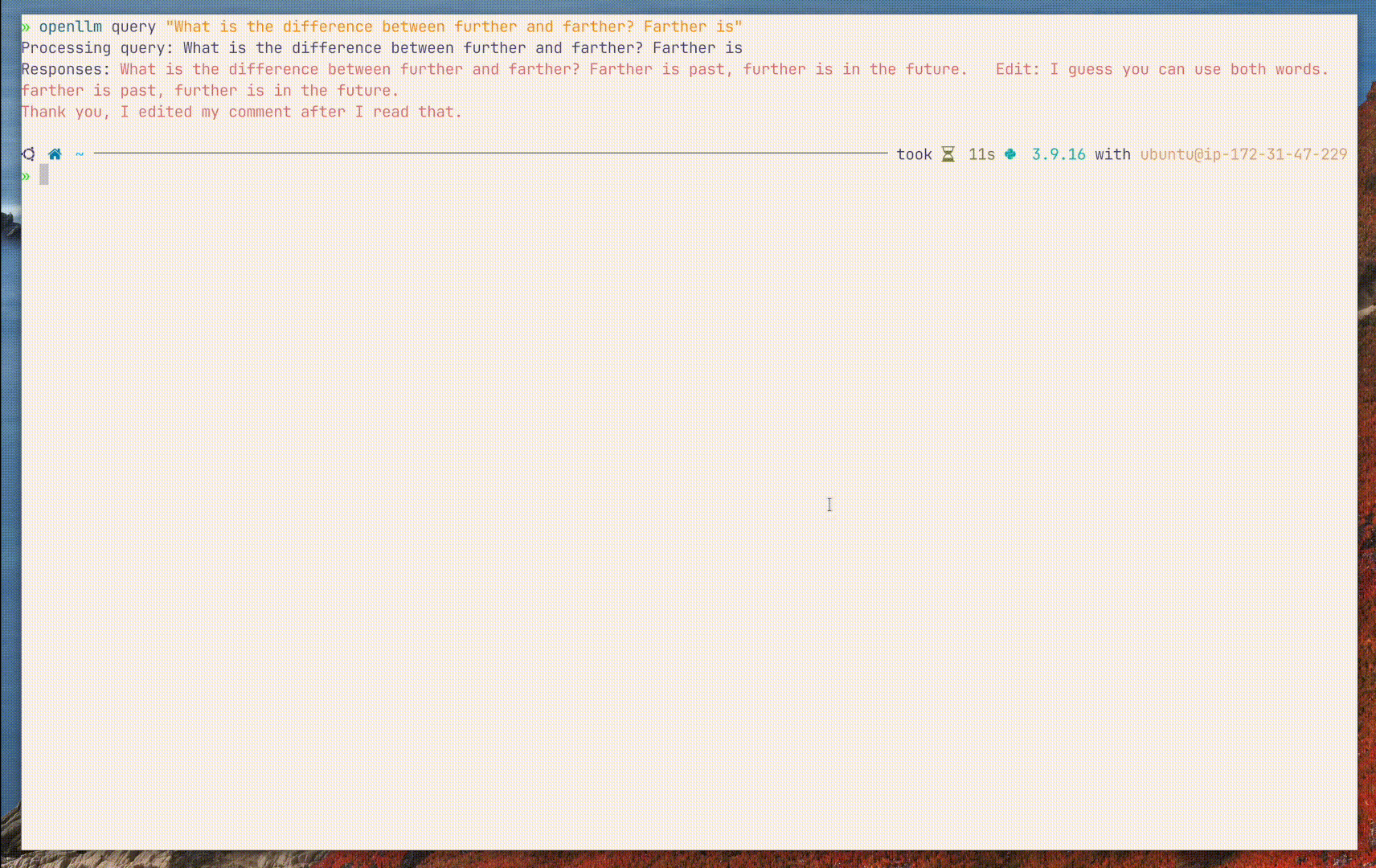
client.query('Explain to me the difference between "further" and "farther"')
Alternatively, use the openllm query command to query the model:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'Explain to me the difference between "further" and "farther"'
OpenLLM seamlessly supports many models and their variants. You can specify different variants of the model to be served. For example:
openllm start <model_id> --<options>
[!NOTE] OpenLLM supports specifying fine-tuning weights and quantized weights for any of the supported models as long as they can be loaded with the model architecture. Use the
openllm modelscommand to see the complete list of supported models, their architectures, and their variants.
[!IMPORTANT] If you are testing OpenLLM on CPU, you might want to pass in
DTYPE=float32. By default, OpenLLM will set modeldtypetobfloat16for the best performance.DTYPE=float32 openllm start microsoft/phi-2This will also applies to older GPUs. If your GPUs doesn't support
bfloat16, then you also want to setDTYPE=float16.
🧩 Supported models
OpenLLM currently supports the following models. By default, OpenLLM doesn't include dependencies to run all models. The extra model-specific dependencies can be installed with the instructions below.
Baichuan
Quickstart
Note: Baichuan requires to install with:
pip install "openllm[baichuan]"
Run the following command to quickly spin up a Baichuan server:
TRUST_REMOTE_CODE=True openllm start baichuan-inc/baichuan-7b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Baichuan variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Baichuan-compatible models.
Supported models
You can specify any of the following Baichuan models via openllm start:
- baichuan-inc/baichuan2-7b-base
- baichuan-inc/baichuan2-7b-chat
- baichuan-inc/baichuan2-13b-base
- baichuan-inc/baichuan2-13b-chat
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start baichuan-inc/baichuan2-7b-base --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start baichuan-inc/baichuan2-7b-base --backend pt
ChatGLM
Quickstart
Note: ChatGLM requires to install with:
pip install "openllm[chatglm]"
Run the following command to quickly spin up a ChatGLM server:
TRUST_REMOTE_CODE=True openllm start thudm/chatglm-6b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any ChatGLM variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more ChatGLM-compatible models.
Supported models
You can specify any of the following ChatGLM models via openllm start:
- thudm/chatglm-6b
- thudm/chatglm-6b-int8
- thudm/chatglm-6b-int4
- thudm/chatglm2-6b
- thudm/chatglm2-6b-int4
- thudm/chatglm3-6b
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start thudm/chatglm-6b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start thudm/chatglm-6b --backend pt
DollyV2
Quickstart
Run the following command to quickly spin up a DollyV2 server:
openllm start databricks/dolly-v2-3b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any DollyV2 variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more DollyV2-compatible models.
Supported models
You can specify any of the following DollyV2 models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start databricks/dolly-v2-3b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start databricks/dolly-v2-3b --backend pt
Falcon
Quickstart
Note: Falcon requires to install with:
pip install "openllm[falcon]"
Run the following command to quickly spin up a Falcon server:
openllm start tiiuae/falcon-7b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Falcon variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Falcon-compatible models.
Supported models
You can specify any of the following Falcon models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start tiiuae/falcon-7b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start tiiuae/falcon-7b --backend pt
FlanT5
Quickstart
Run the following command to quickly spin up a FlanT5 server:
openllm start google/flan-t5-large
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any FlanT5 variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more FlanT5-compatible models.
Supported models
You can specify any of the following FlanT5 models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- PyTorch:
openllm start google/flan-t5-small --backend pt
GPTNeoX
Quickstart
Run the following command to quickly spin up a GPTNeoX server:
openllm start eleutherai/gpt-neox-20b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any GPTNeoX variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more GPTNeoX-compatible models.
Supported models
You can specify any of the following GPTNeoX models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start eleutherai/gpt-neox-20b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start eleutherai/gpt-neox-20b --backend pt
Llama
Quickstart
Run the following command to quickly spin up a Llama server:
openllm start NousResearch/llama-2-7b-hf
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Llama variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Llama-compatible models.
Supported models
You can specify any of the following Llama models via openllm start:
- meta-llama/Llama-2-70b-chat-hf
- meta-llama/Llama-2-13b-chat-hf
- meta-llama/Llama-2-7b-chat-hf
- meta-llama/Llama-2-70b-hf
- meta-llama/Llama-2-13b-hf
- meta-llama/Llama-2-7b-hf
- NousResearch/llama-2-70b-chat-hf
- NousResearch/llama-2-13b-chat-hf
- NousResearch/llama-2-7b-chat-hf
- NousResearch/llama-2-70b-hf
- NousResearch/llama-2-13b-hf
- NousResearch/llama-2-7b-hf
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start meta-llama/Llama-2-70b-chat-hf --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start meta-llama/Llama-2-70b-chat-hf --backend pt
Mistral
Quickstart
Run the following command to quickly spin up a Mistral server:
openllm start mistralai/Mistral-7B-Instruct-v0.1
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Mistral variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Mistral-compatible models.
Supported models
You can specify any of the following Mistral models via openllm start:
- HuggingFaceH4/zephyr-7b-alpha
- HuggingFaceH4/zephyr-7b-beta
- mistralai/Mistral-7B-Instruct-v0.2
- mistralai/Mistral-7B-Instruct-v0.1
- mistralai/Mistral-7B-v0.1
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start HuggingFaceH4/zephyr-7b-alpha --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start HuggingFaceH4/zephyr-7b-alpha --backend pt
Mixtral
Quickstart
Run the following command to quickly spin up a Mixtral server:
openllm start mistralai/Mixtral-8x7B-Instruct-v0.1
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Mixtral variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Mixtral-compatible models.
Supported models
You can specify any of the following Mixtral models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start mistralai/Mixtral-8x7B-Instruct-v0.1 --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start mistralai/Mixtral-8x7B-Instruct-v0.1 --backend pt
MPT
Quickstart
Note: MPT requires to install with:
pip install "openllm[mpt]"
Run the following command to quickly spin up a MPT server:
TRUST_REMOTE_CODE=True openllm start mosaicml/mpt-7b-instruct
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any MPT variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more MPT-compatible models.
Supported models
You can specify any of the following MPT models via openllm start:
- mosaicml/mpt-7b
- mosaicml/mpt-7b-instruct
- mosaicml/mpt-7b-chat
- mosaicml/mpt-7b-storywriter
- mosaicml/mpt-30b
- mosaicml/mpt-30b-instruct
- mosaicml/mpt-30b-chat
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start mosaicml/mpt-7b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start mosaicml/mpt-7b --backend pt
OPT
Quickstart
Run the following command to quickly spin up a OPT server:
openllm start facebook/opt-1.3b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any OPT variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more OPT-compatible models.
Supported models
You can specify any of the following OPT models via openllm start:
- facebook/opt-125m
- facebook/opt-350m
- facebook/opt-1.3b
- facebook/opt-2.7b
- facebook/opt-6.7b
- facebook/opt-66b
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start facebook/opt-125m --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start facebook/opt-125m --backend pt
Phi
Quickstart
Run the following command to quickly spin up a Phi server:
TRUST_REMOTE_CODE=True openllm start microsoft/phi-1_5
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Phi variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Phi-compatible models.
Supported models
You can specify any of the following Phi models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start microsoft/phi-1_5 --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start microsoft/phi-1_5 --backend pt
Qwen
Quickstart
Note: Qwen requires to install with:
pip install "openllm[qwen]"
Run the following command to quickly spin up a Qwen server:
TRUST_REMOTE_CODE=True openllm start qwen/Qwen-7B-Chat
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Qwen variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Qwen-compatible models.
Supported models
You can specify any of the following Qwen models via openllm start:
- qwen/Qwen-7B-Chat
- qwen/Qwen-7B-Chat-Int8
- qwen/Qwen-7B-Chat-Int4
- qwen/Qwen-14B-Chat
- qwen/Qwen-14B-Chat-Int8
- qwen/Qwen-14B-Chat-Int4
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start qwen/Qwen-7B-Chat --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start qwen/Qwen-7B-Chat --backend pt
StableLM
Quickstart
Run the following command to quickly spin up a StableLM server:
openllm start stabilityai/stablelm-tuned-alpha-3b
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any StableLM variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more StableLM-compatible models.
Supported models
You can specify any of the following StableLM models via openllm start:
- stabilityai/stablelm-tuned-alpha-3b
- stabilityai/stablelm-tuned-alpha-7b
- stabilityai/stablelm-base-alpha-3b
- stabilityai/stablelm-base-alpha-7b
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start stabilityai/stablelm-tuned-alpha-3b --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start stabilityai/stablelm-tuned-alpha-3b --backend pt
StarCoder
Quickstart
Note: StarCoder requires to install with:
pip install "openllm[starcoder]"
Run the following command to quickly spin up a StarCoder server:
openllm start bigcode/starcoder
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any StarCoder variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more StarCoder-compatible models.
Supported models
You can specify any of the following StarCoder models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
openllm start bigcode/starcoder --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
openllm start bigcode/starcoder --backend pt
Yi
Quickstart
Run the following command to quickly spin up a Yi server:
TRUST_REMOTE_CODE=True openllm start 01-ai/Yi-6B
In a different terminal, run the following command to interact with the server:
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'What are large language models?'
Note: Any Yi variants can be deployed with OpenLLM. Visit the HuggingFace Model Hub to see more Yi-compatible models.
Supported models
You can specify any of the following Yi models via openllm start:
Supported backends
OpenLLM will support vLLM and PyTorch as default backend. By default, it will use vLLM if vLLM is available, otherwise fallback to PyTorch.
Important: We recommend user to explicitly specify
--backendto choose the desired backend to run the model. If you have access to a GPU, always use--backend vllm.
- vLLM (Recommended):
To install vLLM, run pip install "openllm[vllm]"
TRUST_REMOTE_CODE=True openllm start 01-ai/Yi-6B --backend vllm
Important: Using vLLM requires a GPU that has architecture newer than 8.0 to get the best performance for serving. It is recommended that for all serving usecase in production, you should choose vLLM for serving.
Note: Currently, adapters are yet to be supported with vLLM.
- PyTorch:
TRUST_REMOTE_CODE=True openllm start 01-ai/Yi-6B --backend pt
More models will be integrated with OpenLLM and we welcome your contributions if you want to incorporate your custom LLMs into the ecosystem. Check out Adding a New Model Guide to learn more.
💻 Run your model on multiple GPUs
OpenLLM allows you to start your model server on multiple GPUs and specify the number of workers per resource assigned using the --workers-per-resource option. For example, if you have 4 available GPUs, you set the value as one divided by the number as only one instance of the Runner server will be spawned.
TRUST_REMOTE_CODE=True openllm start microsoft/phi-2 --workers-per-resource 0.25
[!NOTE] The amount of GPUs required depends on the model size itself. You can use the Model Memory Calculator from Hugging Face to calculate how much vRAM is needed to train and perform big model inference on a model and then plan your GPU strategy based on it.
When using the --workers-per-resource option with the openllm build command, the environment variable is saved into the resulting Bento.
For more information, see Resource scheduling strategy.
🛞 Runtime implementations
Different LLMs may support multiple runtime implementations. Models that have vLLM (vllm) supports will use vLLM by default, otherwise it fallback to use PyTorch (pt).
To specify a specific runtime for your chosen model, use the --backend option. For example:
openllm start meta-llama/Llama-2-7b-chat-hf --backend vllm
Note:
- To use the vLLM backend, you need a GPU with at least the Ampere architecture or newer and CUDA version 11.8.
- To see the backend options of each model supported by OpenLLM, see the Supported models section or run
openllm models.
📐 Quantization
Quantization is a technique to reduce the storage and computation requirements for machine learning models, particularly during inference. By approximating floating-point numbers as integers (quantized values), quantization allows for faster computations, reduced memory footprint, and can make it feasible to deploy large models on resource-constrained devices.
OpenLLM supports the following quantization techniques
- LLM.int8(): 8-bit Matrix Multiplication through bitsandbytes
- SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression through bitsandbytes
- AWQ: Activation-aware Weight Quantization,
- GPTQ: Accurate Post-Training Quantization
- SqueezeLLM: Dense-and-Sparse Quantization.
PyTorch backend
With PyTorch backend, OpenLLM supports int8, int4, and gptq.
For using int8 and int4 quantization through bitsandbytes, you can use the following command:
TRUST_REMOTE_CODE=True openllm start microsoft/phi-2 --quantize int8
To run inference with gptq, simply pass --quantize gptq:
openllm start TheBloke/Llama-2-7B-Chat-GPTQ --quantize gptq
[!NOTE] In order to run GPTQ, make sure you run
pip install "openllm[gptq]"first to install the dependency. From the GPTQ paper, it is recommended to quantized the weights before serving. See AutoGPTQ for more information on GPTQ quantization.
vLLM backend
With vLLM backend, OpenLLM supports awq, squeezellm
To run inference with awq, simply pass --quantize awq:
openllm start TheBloke/zephyr-7B-alpha-AWQ --quantize awq
To run inference with squeezellm, simply pass --quantize squeezellm:
openllm start squeeze-ai-lab/sq-llama-2-7b-w4-s0 --quantize squeezellm --serialization legacy
[!IMPORTANT] Since both
squeezellmandawqare weight-aware quantization methods, meaning the quantization is done during training, all pre-trained weights needs to get quantized before inference time. Make sure to find compatible weights on HuggingFace Hub for your model of choice.
🛠️ Serving fine-tuning layers
PEFT, or Parameter-Efficient Fine-Tuning, is a methodology designed to fine-tune pre-trained models more efficiently. Instead of adjusting all model parameters, PEFT focuses on tuning only a subset, reducing computational and storage costs. LoRA (Low-Rank Adaptation) is one of the techniques supported by PEFT. It streamlines fine-tuning by using low-rank decomposition to represent weight updates, thereby drastically reducing the number of trainable parameters.
With OpenLLM, you can take advantage of the fine-tuning feature by serving models with any PEFT-compatible layers using the --adapter-id option. For example:
openllm start facebook/opt-6.7b --adapter-id aarnphm/opt-6-7b-quotes:default
OpenLLM also provides flexibility by supporting adapters from custom file paths:
openllm start facebook/opt-6.7b --adapter-id /path/to/adapters:local_adapter
To use multiple adapters, use the following format:
openllm start facebook/opt-6.7b --adapter-id aarnphm/opt-6.7b-lora:default --adapter-id aarnphm/opt-6.7b-french:french_lora
By default, all adapters will be injected into the models during startup. Adapters can be specified per request via adapter_name:
curl -X 'POST' \
'http://localhost:3000/v1/generate' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the meaning of life?",
"stop": [
"philosopher"
],
"llm_config": {
"max_new_tokens": 256,
"temperature": 0.75,
"top_k": 15,
"top_p": 1
},
"adapter_name": "default"
}'
To include this into the Bento, you can specify the --adapter-id option when using the openllm build command:
openllm build facebook/opt-6.7b --adapter-id ...
If you use a relative path for --adapter-id, you need to add --build-ctx.
openllm build facebook/opt-6.7b --adapter-id ./path/to/adapter_id --build-ctx .
[!IMPORTANT] Fine-tuning support is still experimental and currently only works with PyTorch backend. vLLM support is coming soon.
🐍 Python SDK
Each LLM can be instantiated with openllm.LLM:
import openllm
llm = openllm.LLM('microsoft/phi-2')
The main inference API is the streaming generate_iterator method:
async for generation in llm.generate_iterator('What is the meaning of life?'):
print(generation.outputs[0].text)
[!NOTE] The motivation behind making
llm.generate_iteratoran async generator is to provide support for Continuous batching with vLLM backend. By having the async endpoints, each prompt will be added correctly to the request queue to process with vLLM backend.
There is also a one-shot generate method:
await llm.generate('What is the meaning of life?')
This method is easy to use for one-shot generation use case, but merely served as an example how to use llm.generate_iterator as it uses generate_iterator under the hood.
[!IMPORTANT] If you need to call your code in a synchronous context, you can use
asyncio.runthat wraps an async function:import asyncio async def generate(prompt, **attrs): return await llm.generate(prompt, **attrs) asyncio.run(generate("The meaning of life is", temperature=0.23))
⚙️ Integrations
OpenLLM is not just a standalone product; it's a building block designed to integrate with other powerful tools easily. We currently offer integration with BentoML, OpenAI's Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents.
OpenAI Compatible Endpoints
OpenLLM Server can be used as a drop-in replacement for OpenAI's API. Simply
specify the base_url to llm-endpoint/v1 and you are good to go:
import openai
client = openai.OpenAI(
base_url='http://localhost:3000/v1', api_key='na'
) # Here the server is running on localhost:3000
completions = client.completions.create(
prompt='Write me a tag line for an ice cream shop.', model=model, max_tokens=64, stream=stream
)
The compatible endpoints supports /completions, /chat/completions, and /models
[!NOTE] You can find out OpenAI example clients under the examples folder.
BentoML
OpenLLM LLM can be integrated as a
Runner in your
BentoML service. Simply call await llm.generate to generate text. Note that
llm.generate uses runner under the hood:
import bentoml
import openllm
llm = openllm.LLM('microsoft/phi-2')
svc = bentoml.Service(name='llm-phi-service', runners=[llm.runner])
@svc.api(input=bentoml.io.Text(), output=bentoml.io.Text())
async def prompt(input_text: str) -> str:
generation = await llm.generate(input_text)
return generation.outputs[0].text
LlamaIndex
To start a local LLM with llama_index, simply use llama_index.llms.openllm.OpenLLM:
import asyncio
from llama_index.llms.openllm import OpenLLM
llm = OpenLLM('HuggingFaceH4/zephyr-7b-alpha')
llm.complete('The meaning of life is')
async def main(prompt, **kwargs):
async for it in llm.astream_chat(prompt, **kwargs):
print(it)
asyncio.run(main('The time at San Francisco is'))
If there is a remote LLM Server running elsewhere, then you can use llama_index.llms.openllm.OpenLLMAPI:
from llama_index.llms.openllm import OpenLLMAPI
[!NOTE] All synchronous and asynchronous API from
llama_index.llms.LLMare supported.
LangChain
To quickly start a local LLM with langchain, simply do the following:
from langchain.llms import OpenLLM
llm = OpenLLM(model_name='llama', model_id='meta-llama/Llama-2-7b-hf')
llm('What is the difference between a duck and a goose? And why there are so many Goose in Canada?')
[!IMPORTANT] By default, OpenLLM use
safetensorsformat for saving models. If the model doesn't support safetensors, make sure to passserialisation="legacy"to use the legacy PyTorch bin format.
langchain.llms.OpenLLM has the capability to interact with remote OpenLLM
Server. Given there is an OpenLLM server deployed elsewhere, you can connect to
it by specifying its URL:
from langchain.llms import OpenLLM
llm = OpenLLM(server_url='http://44.23.123.1:3000', server_type='http')
llm('What is the difference between a duck and a goose? And why there are so many Goose in Canada?')
To integrate a LangChain agent with BentoML, you can do the following:
llm = OpenLLM(model_id='google/flan-t5-large', embedded=False, serialisation='legacy')
tools = load_tools(['serpapi', 'llm-math'], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
svc = bentoml.Service('langchain-openllm', runners=[llm.runner])
@svc.api(input=Text(), output=Text())
def chat(input_text: str):
return agent.run(input_text)
[!NOTE] You can find out more examples under the examples folder.
Transformers Agents
OpenLLM seamlessly integrates with Transformers Agents.
[!WARNING] The Transformers Agent is still at an experimental stage. It is recommended to install OpenLLM with
pip install -r nightly-requirements.txtto get the latest API update for HuggingFace agent.
import transformers
agent = transformers.HfAgent('http://localhost:3000/hf/agent') # URL that runs the OpenLLM server
agent.run('Is the following `text` positive or negative?', text="I don't like how this models is generate inputs")

🚀 Deploying models to production
There are several ways to deploy your LLMs:
🐳 Docker container
-
Building a Bento: With OpenLLM, you can easily build a Bento for a specific model, like
mistralai/Mistral-7B-Instruct-v0.1, using thebuildcommand.:openllm build mistralai/Mistral-7B-Instruct-v0.1
A Bento, in BentoML, is the unit of distribution. It packages your program's source code, models, files, artefacts, and dependencies.
-
Containerize your Bento
bentoml containerize <name:version>
This generates a OCI-compatible docker image that can be deployed anywhere docker runs. For best scalability and reliability of your LLM service in production, we recommend deploy with BentoCloud。
☁️ BentoCloud
Deploy OpenLLM with BentoCloud, the serverless cloud for shipping and scaling AI applications.
-
Create a BentoCloud account: sign up here for early access
-
Log into your BentoCloud account:
bentoml cloud login --api-token <your-api-token> --endpoint <bento-cloud-endpoint>
[!NOTE] Replace
<your-api-token>and<bento-cloud-endpoint>with your specific API token and the BentoCloud endpoint respectively.
-
Bulding a Bento: With OpenLLM, you can easily build a Bento for a specific model, such as
mistralai/Mistral-7B-Instruct-v0.1:openllm build mistralai/Mistral-7B-Instruct-v0.1
-
Pushing a Bento: Push your freshly-built Bento service to BentoCloud via the
pushcommand:bentoml push <name:version>
-
Deploying a Bento: Deploy your LLMs to BentoCloud with a single
bentoml deployment createcommand following the deployment instructions.
👥 Community
Engage with like-minded individuals passionate about LLMs, AI, and more on our Discord!
OpenLLM is actively maintained by the BentoML team. Feel free to reach out and join us in our pursuit to make LLMs more accessible and easy to use 👉 Join our Slack community!
🎁 Contributing
We welcome contributions! If you're interested in enhancing OpenLLM's capabilities or have any questions, don't hesitate to reach out in our discord channel.
Checkout our Developer Guide if you wish to contribute to OpenLLM's codebase.
🍇 Telemetry
OpenLLM collects usage data to enhance user experience and improve the product. We only report OpenLLM's internal API calls and ensure maximum privacy by excluding sensitive information. We will never collect user code, model data, or stack traces. For usage tracking, check out the code.
You can opt out of usage tracking by using the --do-not-track CLI option:
openllm [command] --do-not-track
Or by setting the environment variable OPENLLM_DO_NOT_TRACK=True:
export OPENLLM_DO_NOT_TRACK=True
📔 Citation
If you use OpenLLM in your research, we provide a citation to use:
@software{Pham_OpenLLM_Operating_LLMs_2023,
author = {Pham, Aaron and Yang, Chaoyu and Sheng, Sean and Zhao, Shenyang and Lee, Sauyon and Jiang, Bo and Dong, Fog and Guan, Xipeng and Ming, Frost},
license = {Apache-2.0},
month = jun,
title = {{OpenLLM: Operating LLMs in production}},
url = {https://github.com/bentoml/OpenLLM},
year = {2023}
}
Release Information
Changes
- Bump vllm to 0.2.7 for a newly built bento #837
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







