Framework for fast end-to-end multi-agent reinforcement learning on GPUs.



Project description
WarpDrive: Extremely Fast End-to-End Deep Single or Multi-Agent Reinforcement Learning on a GPU
WarpDrive is a flexible, lightweight, and easy-to-use open-source reinforcement learning (RL) framework that implements end-to-end multi-agent RL on a single or multiple GPUs (Graphics Processing Unit).
Using the extreme parallelization capability of GPUs, WarpDrive enables orders-of-magnitude faster RL compared to CPU simulation + GPU model implementations. It is extremely efficient as it avoids back-and-forth data copying between the CPU and the GPU, and runs simulations across multiple agents and multiple environment replicas in parallel.
We have some main updates since its initial open source,
- version 1.3: provides the auto scaling tools to achieve the optimal throughput per device.
- version 1.4: supports the distributed asynchronous training among multiple GPU devices.
- version 1.6: supports the aggregation of multiple GPU blocks for one environment replica.
- version 2.0: supports the dual backends of both CUDA C and JIT compiled Numba. (Our Blog article)
- version 2.6: supports single agent environments, including Cartpole, MountainCar, Acrobot
Together, these allow the user to run thousands or even millions of concurrent simulations and train on extremely large batches of experience, achieving at least 100x throughput over CPU-based counterparts.
Environments
-
We include several default multi-agent environments based on the game of "Tag" for benchmarking and testing. In the "Tag" games, taggers are trying to run after and tag the runners. They are fairly complicated games where thread synchronization, shared memory, high-dimensional indexing for thousands of interacting agents are involved.
-
Several more complex environments such as Covid-19 environment and climate change environment have been developed based on WarpDrive, you may see examples in Real-World Problems and Collaborations.
-
We extend our efforts to some single agent environments including gym.classic_control. Single-agent is a special case of multi-agent environment in WarpDrive. Since each environment only has one agent, the scalability is even higher.
Below, we show multi-agent RL policies trained for different tagger:runner speed ratios using WarpDrive. These environments can run at millions of steps per second, and train in just a few hours, all on a single GPU!



Throughput, Scalability and Convergence
Multi Agent
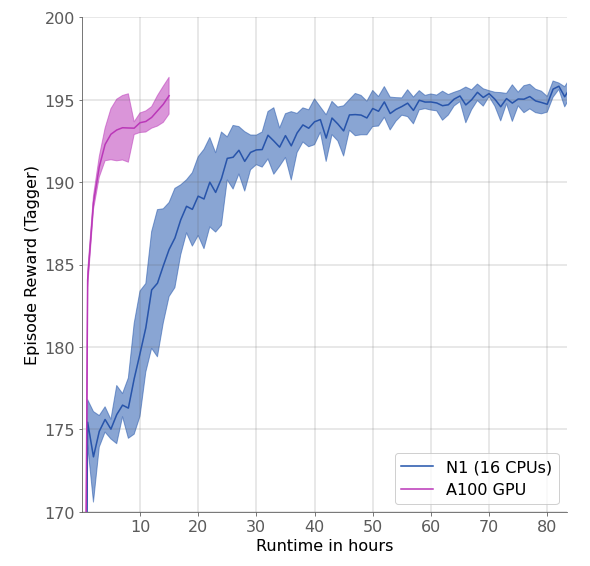
Below, we compare the training speed on an N1 16-CPU node versus a single A100 GPU (using WarpDrive), for the Tag environment with 100 runners and 5 taggers. With the same environment configuration and training parameters, WarpDrive on a GPU is about 10× faster. Both scenarios are with 60 environment replicas running in parallel. Using more environments on the CPU node is infeasible as data copying gets too expensive. With WarpDrive, it is possible to scale up the number of environment replicas at least 10-fold, for even faster training.
Single Agent
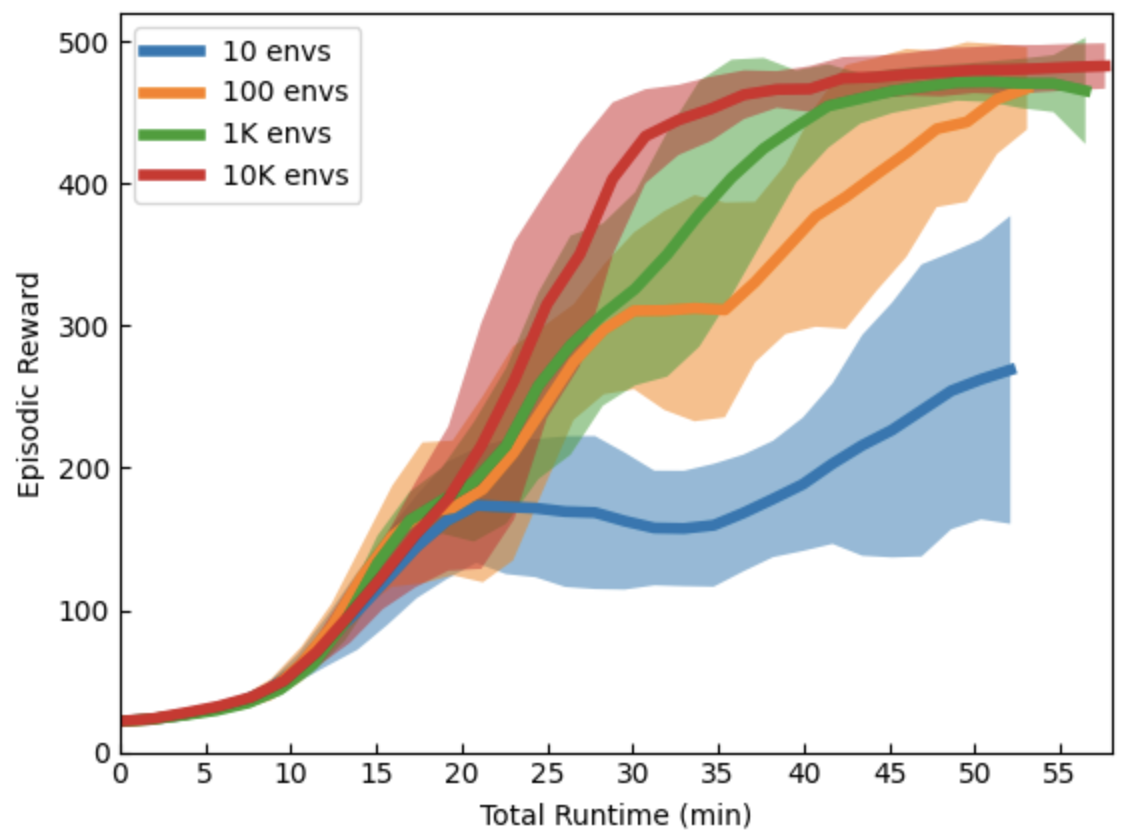
Below, we compare the training speed on a single A100 GPU (using WarpDrive), for the Cartpole-v1 with 10, 100, 1K, and 10K environment replicas running in parallel for 3000 epochs (hyperperams are the same). You may not see elsewhere such an amazing convergence with the number of environments scaled to this large magnitude.
Code Structure
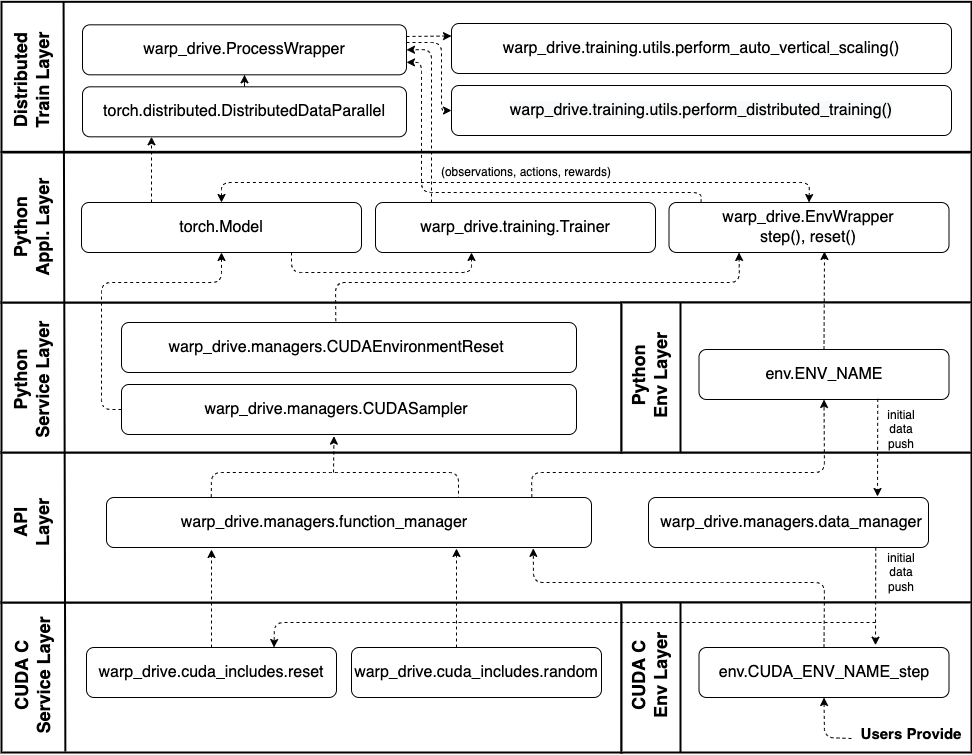
WarpDrive provides a CUDA (or Numba) + Python framework and quality-of-life tools, so you can quickly build fast, flexible and massively distributed multi-agent RL systems. The following figure illustrates a bottoms-up overview of the design and components of WarpDrive. The user only needs to write a CUDA or Numba step function at the CUDA environment layer, while the rest is a pure Python interface. We have step-by-step tutorials for you to master the workflow.
Python Interface
WarpDrive provides tools to build and train multi-agent RL systems quickly with just a few lines of code. Here is a short example to train tagger and runner agents:
# Create a wrapped environment object via the EnvWrapper
# Ensure that env_backend is set to 'pycuda' or 'numba' (in order to run on the GPU)
env_wrapper = EnvWrapper(
TagContinuous(**run_config["env"]),
num_envs=run_config["trainer"]["num_envs"],
env_backend="pycuda"
)
# Agents can share policy models: this dictionary maps policy model names to agent ids.
policy_tag_to_agent_id_map = {
"tagger": list(env_wrapper.env.taggers),
"runner": list(env_wrapper.env.runners),
}
# Create the trainer object
trainer = Trainer(
env_wrapper=env_wrapper,
config=run_config,
policy_tag_to_agent_id_map=policy_tag_to_agent_id_map,
)
# Perform training!
trainer.train()
Papers and Citing WarpDrive
Our paper published at Journal of Machine Learning Research (JMLR) https://jmlr.org/papers/v23/22-0185.html. You can also find more details in our white paper: https://arxiv.org/abs/2108.13976.
If you're using WarpDrive in your research or applications, please cite using this BibTeX:
@article{JMLR:v23:22-0185,
author = {Tian Lan and Sunil Srinivasa and Huan Wang and Stephan Zheng},
title = {WarpDrive: Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {316},
pages = {1--6},
url = {http://jmlr.org/papers/v23/22-0185.html}
}
@misc{lan2021warpdrive,
title={WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU},
author={Tian Lan and Sunil Srinivasa and Huan Wang and Caiming Xiong and Silvio Savarese and Stephan Zheng},
year={2021},
eprint={2108.13976},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Tutorials and Quick Start
Tutorials
Familiarize yourself with WarpDrive by running these tutorials on Colab or NGC container!
- WarpDrive basics(Introdunction and PyCUDA)
- WarpDrive basics(Numba)
- WarpDrive sampler(PyCUDA)
- WarpDrive sampler(Numba)
- WarpDrive resetter and logger
- Create custom environments (PyCUDA)
- Create custom environments (Numba)
- Training with WarpDrive
- Scaling Up training with WarpDrive
- Training with WarpDrive + Pytorch Lightning
You may also run these tutorials locally, but you will need a GPU machine with nvcc compiler installed and a compatible Nvidia GPU driver. You will also need Jupyter. See https://jupyter.readthedocs.io/en/latest/install.html for installation instructions
Example Training Script
We provide some example scripts for you to quickly start the end-to-end training. For example, if you want to train tag_continuous environment (10 taggers and 100 runners) with 2 GPUs and CUDA C backend
python example_training_script_pycuda.py -e tag_continuous -n 2
or switch to JIT compiled Numba backend with 1 GPU
python example_training_script_numba.py -e tag_continuous
You can find full reference documentation here.
Real World Problems and Collaborations
- AI Economist Covid Environment with WarpDrive: We train two-level multi-agent economic simulations using AI-Economist Foundation and train it using WarpDrive. We specifically consider the COVID-19 and economy simulation in this example.
- Climate Change Cooperation Competition collaborated with Mila. We provide the base version of the RICE (regional integrated climate environment) simulation environment.
- Pytorch Lightning Trainer with WarpDrive: We provide a tutorial example and a blog article of a multi-agent reinforcement learning training loop with WarpDrive and Pytorch Lightning.
- NVIDIA NGC Catalog and Quick Deployment to VertexAI: WarpDrive image is hosted by NGC Catalog. The NGC catalog "hosts containers for the top AI and data science software, tuned, tested and optimized by NVIDIA". Our tutorials also enable the quick deployment to VertexAI supported by the NGC.
Installation Instructions
To get started, you'll need to have Python 3.7+ and the nvcc compiler installed with a compatible Nvidia GPU CUDA driver.
CUDA (which includes nvcc) can be installed by following Nvidia's instructions here: https://developer.nvidia.com/cuda-downloads.
Docker Image
V100 GPU: You can refer to the example Dockerfile to configure your system.
A100 GPU: Our latest image is published and maintained by NVIDIA NGC. We recommend you download the latest image from NGC catalog.
If you want to build your customized environment, we suggest you visit Nvidia Docker Hub to download the CUDA and cuDNN images compatible with your system. You should be able to use the command line utility to monitor the NVIDIA GPU devices in your system:
nvidia-smi
and see something like this
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 32W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
In this snapshot, you can see we are using a Tesla V100 GPU and CUDA version 11.0.
Installing using Pip
You can install WarpDrive using the Python package manager:
pip install rl_warp_drive
Installing from Source
-
Clone this repository to your machine:
git clone https://www.github.com/salesforce/warp-drive -
Optional, but recommended for first tries: Create a new conda environment (named "warp_drive" below) and activate it:
conda create --name warp_drive python=3.7 --yes conda activate warp_drive -
Install as an editable Python package:
cd warp_drive pip install -e .
Testing your Installation
You can call directly from Python command to test all modules and the end-to-end training workflow.
python warp_drive/utils/unittests/run_unittests_pycuda.py
python warp_drive/utils/unittests/run_unittests_numba.py
python warp_drive/utils/unittests/run_trainer_tests.py
Learn More
For more information, please check out our blog, white paper, and code documentation.
If you're interested in extending this framework, or have questions, join the AI Economist Slack channel using this invite link.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for rl_warp_drive-2.6.2-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | a7dbd50b6f2cf315eff3bc4c3d70d2169f7ef9363e6e4ccbe3438bb0e5927844 |
|
| MD5 | 6bf8f0a46e166f822afe39ec6ea7f811 |
|
| BLAKE2b-256 | e70169781101b9411a7b625fd4e4f10487dc16299c04fa7c4069d81e50f4a4c8 |







