Discover hidden predictive qualities of features in your dataset by testing them for linear separability after applying different kernel transformations.

Project description
Feature Discovery
Feature Discovery is a machine learning library which aims to make it easier to find non-linear representations of your data that are beneficial for a specific classification task. Instead of manually having to look at a mountain of scree plots whilst trying to figure out how to engineer your feature space, Feature Discovery does the gruntwork for you and tries to come up with a list of promising transformations of the input features for you to look into in more detail.
Why?
Feature engineering is a rather laborious task that needs a lot of domain knowledge and trial&error before you can find quality transformations for a given ML task. Many online tutorials will tell you simply to "look at the data" in order to realize what the perfect transformation is (or kernel if you're intending to use a SVM). Problem is, they do so with a dataset that only has 2 features. What if your dataset has 50 features? That's 50*49/2 = 1225 different scree plots to look at! Ain't nobody got time for that! Now what if we had some kind of tool what would look through your dataset and come up with a prioritized list of promising feature-pairs to look at? This is exactly what Feature Discovery aims to provide. With just a few lines of code, you can have all the features of your dataset checked against common (kernel) transformations and get a quick overview as to where to engineer better features from first. You provide the data, a list of features to look into and kernels to try, and Feature Discovery tries them all and compiles its findings into easily digestible plots or rankings.
Background
A commonly known method for building machine learning models is the kernel method. The idea is to take a data set that isn't linearly separable and make it separable by transforming the data into a higher dimensional space that is.
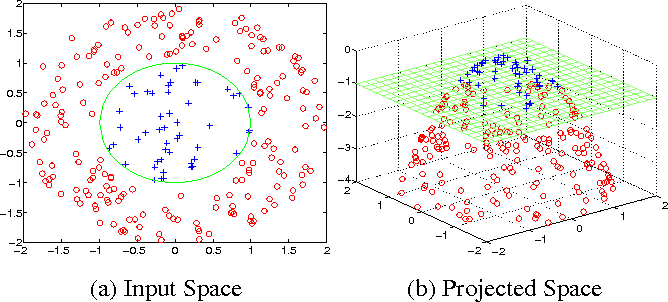
By using a feature map φ(x) you can transform your data into a space that is easier for a machine learning model to tackle. Now a Support Vector Machine would train a linear model using φ(x) and call it a day[^1]. However, if applying φ is beneficial for linear models, it must be beneficial for other models as well and therefore be a good indicator of the hidden potential of a feature.
Currently Supported Kernels
Monovariate
- Quadratic
- Sigmoid
- Logarithmic (shifted & cropped)
Duovariate
- Difference
- Magnitude
- Polynomial (second and third order)
- Random Fourier Functions
- Gaussian (RFF approximation)
Installation
This library minimally requires
- pandas>=1.00
- scipy>=1.7.0
- scikit-learn>=1.0.0
- matplotlib>=3.0.0
- cupy-cuda115>=9.6.0
It is recommended to install cupy via conda beforehand. Afterwards you can install it via pip using:
pip install featurediscovery
How to use
>>> from featurediscovery import kernel_search
>>> df = <your pandas dataframe>
# specify the columns in df that are your feature space
>>> feature_space = ['x0', 'x1', 'x2', 'x3', 'x4', 'x5']
# speficy which column in df is your target variable
>>> target_variable = 'y'
>>> kernel_search.evaluate_kernels(df
, target_variable='y'
, feature_space=feature_space
, monovariate_kernels=['quadratic', 'log']
, duovariate_kernels=['poly3', 'rff_gauss']
, feature_standardizers=['raw']
, plot_feature_ranking=True
, plot_ranking_all_transformations=True
, eval_method='normal'
)
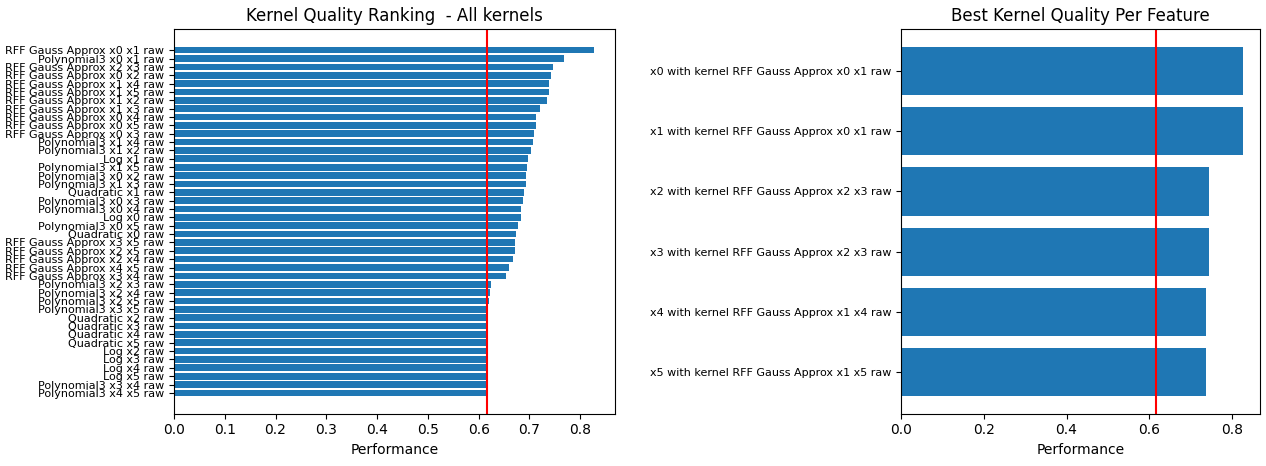
With the two plot parameters enabled two feature priority lists will be generated, a full list of every combination that was evaluated (which can be too much to plot depending on the amount of features/combinations), and a feature ranking which shows per feature only the best kernel transformation that was found. The red vertical line is the prior class probability, meaning a kernel is only beneficial if the model can improve upon this class probability.
Optional parameters
| Parameter | Allowed Values | Function |
|---|---|---|
| plot_feature_ranking | bool: True/False | Plot the feature ranking to screen using the best kernel per feature |
| plot_ranking_all_transformations | bool: True/False | Plot the ranking of every tried kernel to screen |
| plot_individual_kernels | bool: True/False | Plot the result of individual kernels to screen |
| kernel_plot_mode | str: 'scree', 'tsne' | Indicate whether the individual kernels results should be displayed as a (series of) scree plots or as a TSNE plot |
| export_ranking | bool: True/False | Export the ranking to file. Useful for larger jobs. |
| export_individual_kernel_plots | bool: True/False | Export the individual kernel plots to files. Useful for larger jobs. |
| export_folder | str | Path indicating where to store rankings/plots |
| export_formats | list[str]: ['png', 'csv', 'json'] | List of one or more export formats for the kernel rankings. If png is selected, then plots will automatically be generated (so no need to set the plot parameter to true) |
| eval_method | str: 'naive', 'normal', 'full' | How the quality of the kernel should be evaluated. See below for explanation |
| use_cupy | str: 'yes', 'no', 'auto' | Indicate whether or not to use GPU acceleration. GPU acceleration is faster when analyzing larger datasets |
Evaluation methods
Three approaches how the linear separability of the generated kernel features should be evaluated, as specified by the 'eval_method' parameter. These are
- naive: Only generated features are measured for separability. Kernel input features and other raw features are ignored.
- normal: Generated features together with kernel input featues are measured for separability. Other aw features are ignored.
- full: Generated features together with kernel input featues and other raw features are measured for separability. Quality metric here changes to how much the added features improve upon the separability already present in the original dataset.
GPU Acceleration
Running an extensive analysis can be slow when dealing with larger datasets. One way to deal with this is by just enabling the export functions, running the search overnight and looking at the results the next day. But what if you want things to run faster, for instance by running it on the GPU? Well you can! The entire framework is optionally GPU accelerated thanks to CuPy.

For this to work you need to have a CUDA capable GPU in your machine and the CUDA toolkit installed. Installing Feature Discorvery should also install CuPy as a requirement. Then, all you need to do is set the 'use_cupy' parameter to "yes" when running the search.
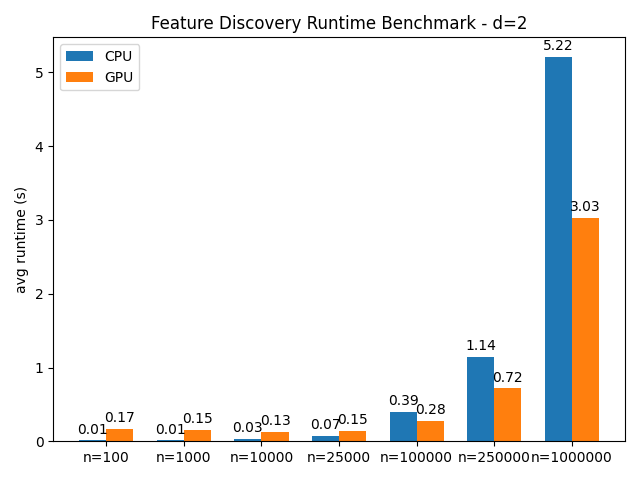
An important factor to note is that this feature isn't universally faster. Preliminary benchmarks have shown that the sample size of the dataset is the biggest determinant w.r.t choosing GPU over CPU. Based on a simple benchmark on a synthetic dataset I would recommend to only enable this feature once your dataset has at least 100k samples.
[^1]: Some kernels like RBF don't do this explicitly and compute the instance similarities differently. For these an explicit mapping can only be approximated.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for featurediscovery-0.1.1-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 2b620c9b9da775ff30102711f9c80053d4704187f99c2782aea87bca515778f9 |
|
| MD5 | 0b7e311a0a30c03eb5da95cf0ceb4f4d |
|
| BLAKE2b-256 | 1e7d9ce7ecd0c824f2c42a66ea3b20e9b65a3ee3864b82d42f94c9bb2aab4493 |







