Masked and Partial Operations for PyTorch

Project description
 PartialTorch
PartialTorch 

PartialTorch is a thin C++ wrapper of PyTorch's operators to support masked and partial semantics.
Main Features
Masked Pair
We use a custom C++ extension class called partialtorch.MaskedPair to store data and mask (an optional
Tensor of the same shape as data, containing 0/1 values indicating the availability of the corresponding
element in data).
The advantages of MaskedPair is that it is statically-typed but unpackable like namedtuple,
and more importantly, it is accepted by torch.jit.script functions as argument or return type.
This container is a temporary substitution for torch.masked.MaskedTensor and may change in the future.
This table compares the two in some aspects:
torch.masked.MaskedTensor |
partialtorch.MaskedPair |
|
|---|---|---|
| Backend | Python | C++ |
| Nature | Is a subclass of Tensor with mask as an additional attribute |
Is a container of data and mask |
| Supported layouts | Strided and Sparse | Only Strided️ |
| Mask types | torch.BoolTensor |
Optional[torch.BoolTensor] (may support other dtypes) |
| Ops Coverage | Listed here (with lots of restrictions) | All masked ops that torch.masked.MaskedTensor supports and more |
torch.jit.script-able |
Yes✔️ (Python ops seem not to be jit compiled but encapsulated) | Yes✔️ |
Supports Tensor's methods |
Yes✔️ | Only a few[^1] |
Supports __torch_function__ |
Yes✔️ | No❌[^1] |
| Performance | Slow and sometimes buggy (e.g. try calling .backward 3 times) |
Faster, not prone to bugs related to autograd as it is a container |
[^1]: We blame torch 😅
More details about the differences will be discussed below.
Masked Operators
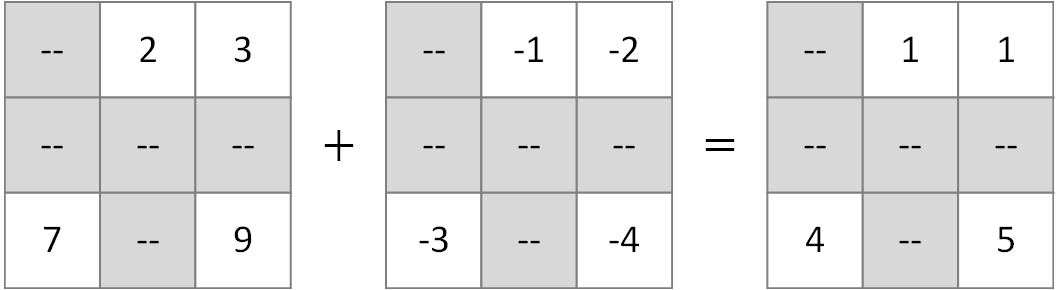

Masked operators are the same things that can be found in torch.masked
package (which is, unfortunately, still in prototype stage).
Our semantic differs from torch.masked for non-unary operators.
torch.masked: Requires operands to share identical mask (check this link), which is not always the case when we have to deal with missing data.partialtorch: Allows operands to have different masks, the output mask is the result of a bitwise all function of input masks' values.
Partial Operators
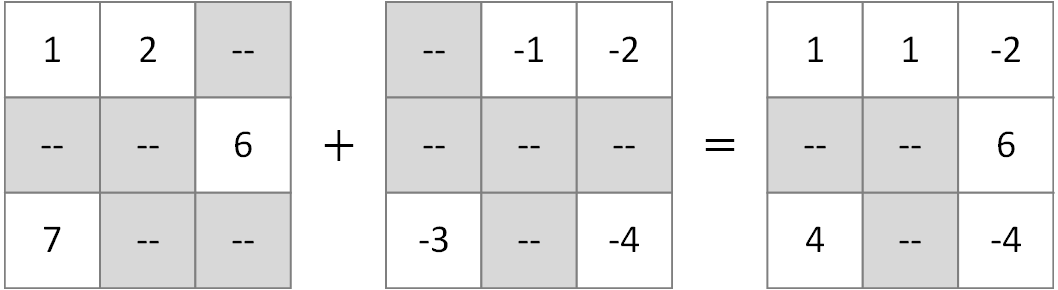
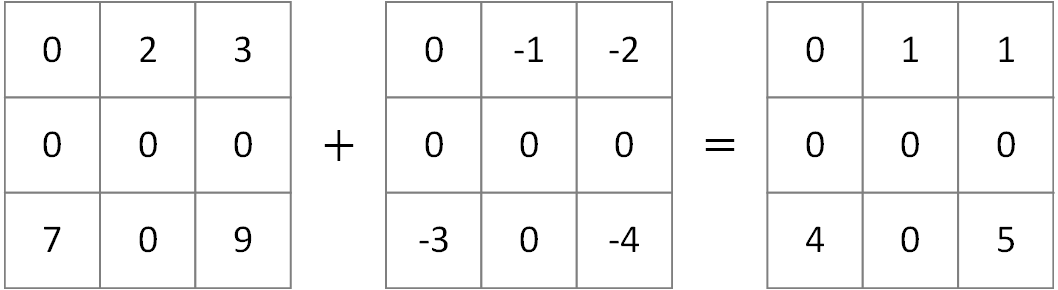
Similar to masked operators, partial operators allow non-uniform masks but instead of using bitwise all to compute output mask, they use bitwise any. That means output at any position with at least one present operand is NOT considered missing.
In details, before fowarding to the regular torch native operators, the masked positions of each operand are filled
with an identity value.
The identity value is defined as the initial value that has the property op(op_identity, value) = value.
For example, the identity value of element-wise addition is 0.
All partial operators have a prefix partial_ prepended to their name (e.g. partialtorch.partial_add),
while masked operators inherit their native ops' names.
Reduction operators are excluded from this rule as they can be considered unary partial, and some of them
are already available in torch.masked.
Scaled Partial Operators

Some partial operators that involves addition/substraction are extended to have rescaling semantic.
We call them scaled partial operators.
In essence, they rescale the output by the ratio of present operands in the computation of the output.
The idea is similar to torch.dropout rescaling by $\frac{1}{1-p}$,
or more precisely the way Partial Convolution works.
Programatically, all scaled partial operators share the same signature with their non-scaled counterparts,
and are dispatched to when adding a keyword-only argument scaled = True:
pout = partialtorch.partial_add(pa, pb, scaled=True)
Torch Ops Coverage
We found out that the workload is behemoth for a group of one person, and involves manually reimplementing all
native functors under the at::_ops namespace (guess how many there are).
Therefore, we try to cover as many primitive operators as possible, as well as a few other operators relevant to our
work.
The full list of all registered signatures can be found in this file.
If you want any operator to be added, please contact me. But if they fall into one of the following categories, the porting may take long or will not happen:
- Ops that do not have a meaningful masked semantic (e.g.
torch.det). - Ops that cannot be implemented easily by calling native ops and requires writing custom kernels (e.g.
torch.mode). - Ops that accept output as an input a.k.a. out ops (e.g.
aten::mul.out(self: Tensor, other: Tensor, *, out: Tensor(a!)) -> Tensor(a!)). - Ops for tensors with unsuported properties (e.g. named tensors, sparse/quantized layouts).
- Ops with any input/return type that do not have
pybind11type conversions predefined bytorch's C++ backend.
Also, everyone is welcome to contribute.
Requirements
torch>=2.1.0(this version of PyTorch brought a number of changes that are not backward compatible)
Installation
From TestPyPI
partialtorch has wheels hosted at TestPyPI (it is not likely to reach a stable state anytime soon):
pip install -i https://test.pypi.org/simple/ partialtorch
The Linux and Windows wheels are built with Cuda 12.1. If you cannot find a wheel for your Arch/Python/Cuda, or there is any problem with library linking when importing, proceed to instructions to build from source.
| Linux/Windows | MacOS | |
|---|---|---|
| Python version: | 3.8-3.11 | 3.8-3.11 |
| PyTorch version: | torch==2.1.0 |
torch==2.1.0 |
| Cuda version: | 12.1 | - |
| GPU CCs: | 5.0,6.0,6.1,7.0,7.5,8.0,8.6,9.0+PTX |
- |
From Source
For installing from source, you need a C++17 compiler (gcc/msvc) and a Cuda compiler (nvcc) installed.
Then, clone this repo and execute:
pip install .
Usage
Initializing a MaskedPair
While MaskedPair is almost as simple as a namedtuple, there are also a few supporting creation ops:
import torch, partialtorch
x = torch.rand(3, 3)
x_mask = torch.bernoulli(torch.full_like(x, 0.5)).bool() # x_mask must have dtype torch.bool
px = partialtorch.masked_pair(x, x_mask) # with 2 inputs data and mask
px = partialtorch.masked_pair(x) # with data only (mask = None)
px = partialtorch.masked_pair(x, None) # explicitly define mask = None
px = partialtorch.masked_pair(x, True) # explicitly define mask = True (equivalent to None)
px = partialtorch.masked_pair((x, x_mask)) # from tuple
# this new random function conveniently does the work of the above steps
px = partialtorch.rand_mask(x, 0.5)
Note that MaskedPair is not a subclass of Tensor like MaskedTensor,
so we only support a very limited number of methods.
This is mostly because of the current limitations of C++ backend for custom classes[^1] such as:
- Unable to overload methods with the same name
- Unable to define custom type conversions from Python type (
Tensor) or to custom Python type (to be able to define custom methods such as__str__ofTensordoes for example) - Unable to define
__torch_function__
In the meantime, please consider MaskedPair purely a fast container and use
partialtorch.op(pair, ...) instead of pair.op(...) if not available.
Note: You cannot index MaskedPair with pair[..., 1:-1] as they acts like tuple of 2 elements when indexed.
Operators
All registered ops can be accessed like any torch's custom C++ operator by calling torch.ops.partialtorch.[op_name]
(the same way we call native ATen function torch.ops.aten.[op_name]).
Their overloaded versions that accept Tensor are also registered for convenience
(but return type is always converted to MaskedPair).
| torch | partialtorch |
|---|---|
import torch
torch.manual_seed(1)
x = torch.rand(5, 5)
y = torch.sum(x, 0, keepdim=True)
|
import torch
import partialtorch
torch.manual_seed(1)
x = torch.rand(5, 5)
px = partialtorch.rand_mask(x, 0.5)
# standard extension ops calling
pout = torch.ops.partialtorch.sum(px, 0, keepdim=True)
# all exposed ops are also aliased inside partialtorch.ops
pout = partialtorch.ops.sum(px, 0, keepdim=True)
|
Furthermore, we inherit the naming convention of for inplace ops - appending a trailing _ character after their
names (e.g. partialtorch.relu and partialtorch.relu_).
They modify both data and mask of the first operand inplacely.
The usage is kept as close to the corresponding Tensor ops as possible.
Hence, further explaination is redundant.
Neural Network Layers
Currently, there are only a number of modules implemented in partialtorch.nn subpackage that are masked equivalences
of those in torch.nn.
This is the list of submodules inside partialtorch.nn.modules and the layers they provide:
partialtorch.nn.modules.activation: All activations excepttorch.nn.MultiheadAttentionpartialtorch.nn.modules.batchnorm:BatchNormNdpartialtorch.nn.modules.channelshuffle:ChannelShufflepartialtorch.nn.modules.conv:PartialConvNd,PartialConvTransposeNdpartialtorch.nn.modules.dropout:DropoutNd,AlphaDropout,FeatureAlphaDropoutpartialtorch.nn.modules.flatten:Flatten,Unflattenpartialtorch.nn.modules.fold:Fold,Unfoldpartialtorch.nn.modules.instancenorm:InstanceNormNdpartialtorch.nn.modules.normalization:LayerNormpartialtorch.nn.modules.padding:CircularPadNd,ConstantPadNd,ReflectionPadNd,ReplicationPadNd,ZeroPadNdpartialtorch.nn.modules.pixelshuffle:PixelShuffle,PixelUnshufflepartialtorch.nn.modules.pooling:MaxPoolNd,AvgPoolNd,FractionalMaxPoolNd,LpPoolNd,AdaptiveMaxPoolNd,AdaptiveAvgPoolNdpartialtorch.nn.modules.upsampling:Upsample,UpsamplingNearest2d,UpsamplingBilinear2d,PartialUpsample,PartialUpsamplingBilinear2d
The steps for declaring your custom module is identical, except that we now use the classes inside partialtorch.nn
which input and output MaskedPair.
Note that to make them scriptable, you may have to explicitly annotate input and output types.
| torch | partialtorch |
|---|---|
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
self.conv = nn.Conv2d(in_channels,
out_channels,
kernel_size=(3, 3))
self.bn = nn.BatchNorm2d(out_channels)
self.pool = nn.MaxPool2d(kernel_size=(2, 2))
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = F.relu(x)
x = self.bn(x)
x = self.pool(x)
return x
|
import torch.nn as nn
import partialtorch.nn as partial_nn
import partialtorch.nn.functional as partial_F
from partialtorch import MaskedPair
class PartialConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
self.conv = partial_nn.PartialConv2d(in_channels,
out_channels,
kernel_size=(3, 3))
self.bn = partial_nn.BatchNorm2d(out_channels)
self.pool = partial_nn.MaxPool2d(kernel_size=(2, 2))
def forward(self, x: MaskedPair) -> MaskedPair:
x = self.conv(x)
x = partial_F.relu(x)
x = self.bn(x)
x = self.pool(x)
return x
|
A few other examples can be found in examples folder.
Citation
This code is part of another project of us. Citation will be added in the future.
Acknowledgements
Part of the codebase is modified from the following repositories:
License
The code is released under the MIT license. See LICENSE.txt for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Hashes for partialtorch-0.0.8-cp311-cp311-win_amd64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 15fd47a2ce714ee9b9f8280061228999107e74443bfb03157078021e373afa6a |
|
| MD5 | a643426078d2abedd0ce7ab21003dc81 |
|
| BLAKE2b-256 | 7ee8b9b1e15f497c6eb86baaa3800c3c5040aab7c721331b9408c0f2870fc9c2 |
Hashes for partialtorch-0.0.8-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | fcd1d0d0441742de0c9ae5bf4e790a7825758ac93748efd7d627d8ac5ad118fa |
|
| MD5 | 21b8fd681b261355dd48a3427f55ed25 |
|
| BLAKE2b-256 | b7d8d2d82c278011be2c14434a33e766ba27fb753805747488570ed79812e315 |
Hashes for partialtorch-0.0.8-cp311-cp311-macosx_10_9_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 86556280219c0db7e09db4df2fcbc31bf69b33812a3e4ebe139e3bf8ba966352 |
|
| MD5 | 3a47c37acf00bc9c035d2a17016daa1b |
|
| BLAKE2b-256 | 30b66c40e44a55138a55c3e66ce17d4f9ad4e52654e2841cce44c0564f3b31d3 |
Hashes for partialtorch-0.0.8-cp310-cp310-win_amd64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 748c3ae04db4315d4e83d5a0c6ed7b674669244a6ca20217c3aef120a9067938 |
|
| MD5 | c186cd245266231d821b002a402bd5ff |
|
| BLAKE2b-256 | a266712ade4b03e15c2232a70526f5ca8a91b467f3faaa2e4d1743d57a5e9018 |
Hashes for partialtorch-0.0.8-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 4031ea436efdf0e153f812c6d1cf1185b5436b62b6720bffac85562643ed8daf |
|
| MD5 | 15c3342b2ae0acd4d8e4ac7e67a05e99 |
|
| BLAKE2b-256 | d5c31c345bfb77f104683495364cdd6fd928b95f9a1102ac11208fb2c3c355ad |
Hashes for partialtorch-0.0.8-cp310-cp310-macosx_10_9_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 7146da40d51a9af1b029e00822d31bad644be10ae89c24f87efb08ec667259a6 |
|
| MD5 | f9a4dadb6a7f3ca08a0c8a29f6832d3b |
|
| BLAKE2b-256 | 6f8371df3d18726979854312a8341101f928b4eb98fd26cb02e3e91f8edfff88 |
Hashes for partialtorch-0.0.8-cp39-cp39-win_amd64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 9d06573811ccb00520ccc990584a3e0253364e78cd598b5f9d7c28411daf35b8 |
|
| MD5 | 8b9b8fb93e6df5b53805713fe052fd36 |
|
| BLAKE2b-256 | 19e404df426d43b5a784952d2ce98623a1bbb1ff6e6c918b968ebc61fa1602c4 |
Hashes for partialtorch-0.0.8-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 12416b57ee0b656a49a9d06ab2b3527b5b74892198995cfc93626e75f418c60b |
|
| MD5 | 06406170ad06332dbfd9bea385e7be33 |
|
| BLAKE2b-256 | 5e7462607dbae6725a06aee379a08b3c0b389d8929c177d9843a6c17ef171152 |
Hashes for partialtorch-0.0.8-cp39-cp39-macosx_10_9_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 5bb821034bea398b5a995668b83895680bf7f5855a5fc913b09afc867bb81509 |
|
| MD5 | 6d0f656f85365cca256681d580779e14 |
|
| BLAKE2b-256 | 3f96f6f4ac3e714312e93d473ed159084bd3e5a2f099ff8ebc1169f3af783f2f |
Hashes for partialtorch-0.0.8-cp38-cp38-win_amd64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | cd92aad28cae1f78ff3ba35798543a2e03a13af1bd9703d09fe1e26641f37cfa |
|
| MD5 | 0ca3502569b320c0b8d440ba72cdef83 |
|
| BLAKE2b-256 | 79c7f94827f4a73e20ae664337a416f3bd3c939adb78b0c55222b3ab3aee6bf6 |
Hashes for partialtorch-0.0.8-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 6fd30da81fb62416f8e7f69cf49030b0c3586e389a9fdf0c9c688608974816ea |
|
| MD5 | 731523e51f051617fe51f40c29d87b0b |
|
| BLAKE2b-256 | bb9aa7d5f4be3e78c07d949d007c354e2cc92bf19b515ee58d9adb7cbf6ad21d |
Hashes for partialtorch-0.0.8-cp38-cp38-macosx_10_9_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 8193aaf7ada15d61a429e3c77a887814327c6791d75d177770390ce5688e0232 |
|
| MD5 | ba4e5a0169a534ed8232f0e1774ff316 |
|
| BLAKE2b-256 | 07f1afec0fb4cfc574166c77aafc950c867865b8e14382a986910f9234447ec7 |







